Abstract
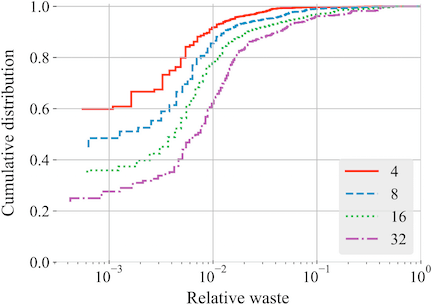
Accurate and efficient methods for solving stiff ordinary differential equations (ODEs) are a critical component of turbulent combustion simulations with finite-rate chemistry. The ODEs governing the chemical kinetics at each mesh point are decoupled by operator-splitting allowing each to be solved concurrently. An efficient ODE solver must then take into account the available thread and instruction-level parallelism of the underlying hardware, especially on many-core coprocessors, as well as the numerical efficiency. A stiff Rosenbrock and a nonstiff Runge–Kutta ODE solver are both implemented using the single instruction, multiple thread (SIMT) and single instruction, multiple data (SIMD) paradigms within OpenCL. Both methods solve multiple ODEs concurrently within the same instruction stream. The performance of these parallel implementations was measured on three chemical kinetic models of increasing size across several multicore and many-core platforms. Two separate benchmarks were conducted to clearly determine any performance advantage offered by either method. The first benchmark measured the run-time of evaluating the right-hand-side source terms in parallel and the second benchmark integrated a series of constant-pressure, homogeneous reactors using the Rosenbrock and Runge–Kutta solvers. The right-hand-side evaluations with SIMD parallelism on the host multicore Xeon CPU and many-core Xeon Phi co-processor performed approximately three times faster than the baseline multithreaded C++ code. The SIMT parallel model on the host and Phi was 13%–35% slower than the baseline while the SIMT model on the NVIDIA Kepler GPU provided approximately the same performance as the SIMD model on the Phi. The runtimes for both ODE solvers decreased significantly with the SIMD implementations on the host CPU (2.5–2.7x) and Xeon Phi coprocessor (4.7–4.9x) compared to the baseline parallel code. The SIMT implementations on the GPU ran 1.5–1.6 times faster than the baseline multithreaded CPU code; however, this was significantly slower than the SIMD versions on the host CPU or the Xeon Phi. The performance difference between the three platforms was attributed to thread divergence caused by the adaptive step-sizes within the ODE integrators. Analysis showed that the wider vector width of the GPU incurs a higher level of divergence than the narrower Sandy Bridge or Xeon Phi. The significant performance improvement provided by the SIMD parallel strategy motivates further research into more ODE solver methods that are both SIMD-friendly and computationally efficient.